
ARM introduced its CoreLink CCN-504 cache coherent network this morning at the Linley Tech Processor Conference in San Jose, California.
According to ARM senior product manager Ian Forsyth, the CoreLink CCN-504 is capable of delivering up to one terabit of usable system bandwidth per second.
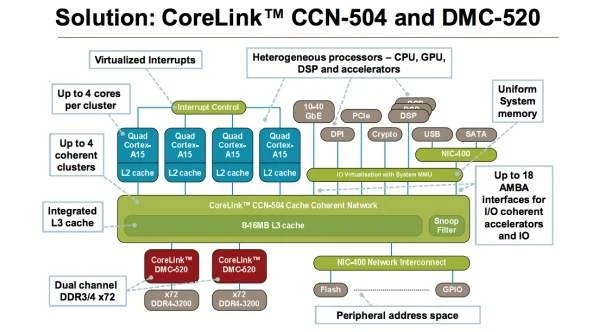
“This will allow SoC designers to provide high-performance, cache coherent interconnect for ‘many-core’ enterprise solutions [up to 16 cores] built using the ARM Cortex-A15 MPCore processor and next-generation 64-bit processors,” Forsyth told TG Daily on the sidelines of the conference.
Forsyth also confirmed that LSI and Calxeda are currently “lead licensees” for the CoreLink CCN-504.
In addition to the CoreLink CCN-504, ARM debuted the CoreLink DMC-520 dynamic memory controller which is specifically designed to be paired with the CCN-504. The new dynamic memory controller offers up a high-bandwidth interface to shared off-chip memory, such as DDR3, DDR3L and DDR4 DRAM.
“Essentially, CoreLink CCN-504 is the first in a family of products. It enables a fully-coherent, high-performance many-core solution that supports up to 16 cores on the same silicon die. The architecture also enables system coherency in heterogeneous multicore and multi-cluster CPU/GPU systems by enabling each processor in the system to access the other processor caches,” Forsyth explained.
”This reduces the need to access off-chip memory, saving time and energy, which is a key enabler in systems based on ARM big.LITTLE processing, a new paradigm that can deliver both high-performance, required for content creation and consumption, and extreme power efficiency for extended battery life.”
Indeed, the CoreLink CCN-504 supports both the current-generation high-end Cortex-A15 processor and future ARMv8 processors. It also features level 3 (L3) cache along with snoop filter functions.
The L3 cache, which is configurable up to 16MB, extends on-chip caching for demanding workloads and offers low latency on-chip memory for allocation and sharing of data between processors, high-speed IO interfaces and accelerators. The snoop filter removes the need for broadcast coherency messaging, further reducing latency and power.




